I've been spending some time thinking about the ramifications of centralized identity plays coming back into vogue with the release of Facebook Connect, MySpaceID and Google's weird amalgam Google Friend Connect. Slowly I began to draw parallels between the current situation and a different online technology battle from half a decade ago.
About five years ago, one of the most contentious issues among Web geeks was the RSS versus Atom debate. On the one hand there was RSS 2.0, a widely deployed and fairly straightforward XML syndication format which had some ambiguity around the spec but whose benevolent dictator had declared the spec frozen to stabilize the ecosystem around the technology. On the other hand you had the Atom syndication format, an up and coming XML syndication format backed by a big company (Google) and a number of big names in the Web standards world (Tim Bray, Sam Ruby, Mark Pilgrim, etc) which intended to do XML syndication the right way and address some of the flaws of RSS 2.0.
During that time I was an RSS 2.0 backer even though I spent enough time on the atom-syntax mailing list to be named as a contributor on the final RFC. My reasons for supporting RSS 2.0 are captured in my five year old blog post The ATOM API vs. the ATOM Syndication Format which contained the following excerpt
Based on my experiences working with syndication software as a hobbyist developer for the past year is that the ATOM syndication format does not offer much (if anything) over RSS 2.0 but that the ATOM API looks to be a significant step forward compared to previous attempts at weblog editing/management APIs especially with regard to extensibility, support for modern practices around service oriented architecture, and security.
...
Regardless of what ends up happening, the ATOM API is best poised to be the future of weblog editting APIs. The ATOM syndication format on the other hand...
My perspective was that the Atom syndication format was a burden on consumers of feeds since it meant they had to add yet another XML syndication format to the list of formats they supported; RSS 0.91, RSS 1.0, RSS 2.0 and now Atom. However the Atom Publishing Protocol (AtomPub) was clearly an improvement to the state of the art at the time and was a welcome addition to the blog software ecosystem. It would have been the best of both worlds if AtomPub simply used RSS 2.0 so we got the benefits with none of the pain of duplicate syndication formats.
As time has passed, it looks like I was both right and wrong about how things would turn out. The Atom Publishing Protocol has been more successful than I could have ever imagined. It not only became a key blog editing API but evolved to become a key technology for accessing data from cloud based sources that has been embraced by big software companies like Google (GData) and Microsoft (ADO.NET Data Services, Live Framework, etc). This is where I was right.
I was wrong about how much of a burden having XML syndication formats would be on developers and end users. Although it is unfortunate that every consumer of XML feed formats has to write code to process both RSS and Atom feeds, this has not been a big deal. For one, this code has quickly been abstracted out into libraries on the majority of popular platforms so only a few developers have had to deal with it. Similarly end users also haven't had to deal with this fragmentation that much. At first some sites did put out feeds in multiple formats which just ended up confusing users but that is mostly a thing of the past. Today most end users interacting with feeds have no reason to know about the distinction between Atom or RSS since for the most part there is none when you are consuming the feed from Google Reader, RSS Bandit or your favorite RSS reader.
I was reminded by this turn of events when reading John McCrea's post As Online Identity War Breaks Out, JanRain Becomes “Switzerland” where he wrote
Until now, JanRain has been a pureplay OpenID solution provider, hoping to build a business just on OpenID, the promising open standard for single sign-on. But the company has now added Facebook as a proprietary login choice amidst the various OpenID options on RPX, a move that shifts them into a more neutral stance, straddling the Facebook and “Open Stack” camps. In my view, that puts JanRain in the interesting and enviable position of being the “Switzerland” of the emerging online identity wars.
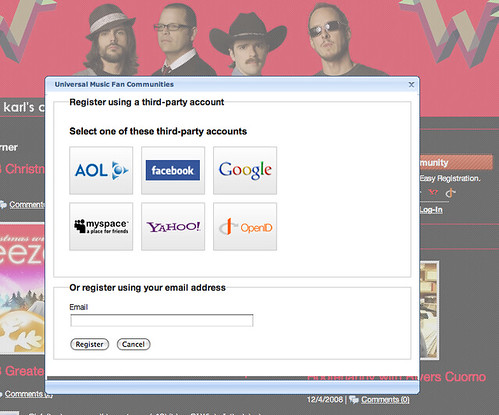
For site operators, RPX offers an economical way to integrate the non-core function of “login via third-party identity providers” at a time when the choices in that space are growing and evolving rapidly. So, rather than direct its own technical resources to integrating Facebook Connect and the various OpenID implementations from MySpace, Google, Yahoo, AOL, Microsoft, along with plain vanilla OpenID, a site operator can simply outsource all of those headaches to JanRain.
Just as standard libraries like the Universal Feed Parser and the Windows RSS platform insulated developers from the RSS vs. Atom formatwar, JanRain's RPX makes it so that individual developers don't have to worry about the differences between supporting proprietary technologies like Facebook Connect or Open Stack™ technologies like OpenID.
At the end of the day, it is quite likely that the underlying technologies will not matter to matter to anyone but a handful of Web standards geeks and library developers. Instead what is important is for sites to participate in the growing identity provider ecosystem not what technology they use to do so.
 Now Playing: Yung Wun featuring DMX, Lil' Flip & David Banner - Tear It Up
Now Playing: Yung Wun featuring DMX, Lil' Flip & David Banner - Tear It Up