Earlier this morning I was reading a number of comments in response to a submission on reddit.com where I found out that despite being a regular visitor to the site there were multiple useful features I was completely unaware of. Here's a list of features I discovered the site has that I hadn't noticed even though I visit it multiple times a day
These are all clearly useful features. In fact, some of them are features I'd have lobbied for if ever asked what features I'd like to see added to reddit even though they already existed. Considering that I'm a fairly savvy Web user and visit the site multiple times a day, it is problematic that I'm unaware of valuable features of the site which were the result of valuable effort from the developers at reddit.
This is a very commonplace occurrence in software development. As applications add features without wanting to clutter the interface, they begin to "hide" these features until it gets to the point where their users end up clamoring or pining for features that actually already exist in the application. A famous example of this comes from Jensen Harris' series of posts on the UI changes in Office 2007. There is rather informative post entitled New Rectangles to the Rescue? (Why the UI, Part 4) which contains the following excerpt
Contrary to the conventional wisdom of the naysayers, we weren't (and aren't) "out of ideas" for Office. Customers weren't telling us that they didn't need new features--to the contrary, the list of requests is a mile long. Every version we were putting our heart and soul into developing these new features, undergoing a rigorous process to determine which of the many areas we would invest in during a release, and then working hard to design, test, and ship those features. The only problem was that people weren't finding the very features they asked us to add.
To address the issue above, the Office team effectively dedicated a release to making their existing features discoverable1. This isn't the only example of a popular application dedicating a release to making features more discoverable instead of adding new features. The Facebook redesign of last year is another famous example of this which has lead to increased usage of the site.
A recent TechCrunch article, Facebook Photos Pulls Away From The Pack shows the effect of the redesign on the usage of the site
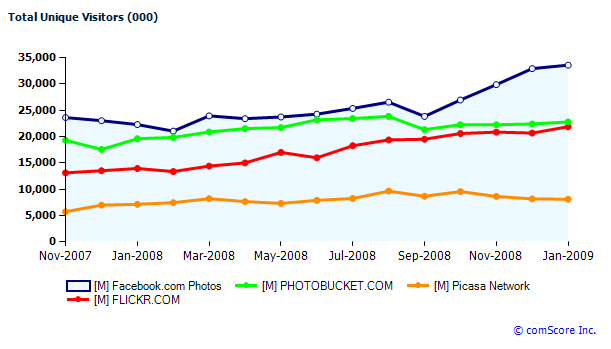
...
What accounts for Facebook’s advantage in the photo department? The biggest factor is simply that it is the default photo feature of the largest social network in the world. And of all the viral loops that Facebook benefits from, its Photos app might have the largest viral loop of all built into it. Whenever one of your friends tags a photo with your name, you get an email. This single feature turns a solitary chore—tagging and organizing photos—into a powerful form of communication that connects people through activities they’ve done in the past in an immediate, visual way. I would not be surprised if people click back through to Facebook from those photo notifications at a higher rate than from any other notification, including private messages.
But the tagging feature has been part of Facebook Photos for a long time. What happened in September to accelerate growth? That is when a Facebook redesign went into effect which added a Photos tab on everyone’s personal homepage.
The lesson here is that having a feature isn't enough, making sure your users can easily find and use the feature is just as important. In addition, sometimes the best thing to do for your product isn't to add new features but to make sure the existing features are giving users the best experience.
When you do find out that usage of a feature is low given it's usefulness and relevance to your user base, this is a good time to invest in an experimentation platform where you can perform A/B testing (aka split testing) and multivariate testing. There are a number of off-the-shelf tools for performing such experiments which enable you to test and validate potential redesigns today without unleashing potentially negatively impacting changes to your entire user base.
1I believe the Office team shipped lots of new features as well in Office 2007, however the biggest change from an end user's perspective was the redesign not new features.
 Now Playing: Metallica - Harvester of Sorrow
Now Playing: Metallica - Harvester of Sorrow